Насколько сейчас прогнозы лучше, чем раньше?
Изменения в программе Google-переводчик иллюстрируют, как машинное обучение (один из его подразделов – глубокое обучение) снижает цену на качественные прогнозы. За ту же цену в единицах вычислительной мощности Google предоставляет перевод более высокого качества. Цена прогнозов аналогичного качества значительно снизилась.
Инновации в прогностических технологиях влияют на традиционно связанные с прогнозом сферы, такие как обнаружение финансового мошенничества. Здесь наблюдается такой прогресс, что эмитенты кредитных карт выявляют и пресекают случаи мошенничества раньше, чем пользователи успевают их заметить. И все же улучшение происходит постепенно. В конце 1990-х с помощью передовых тогда методов удавалось предотвратить около 80 % мошеннических транзакций[20]. К 2000 году эти показатели поднялись до 90–95 %, а сегодня достигают 98–99,9 %[21]. Последний рывок стал результатом машинного обучения: разница между 98 и 99,9 % огромна.
Кажется, что от 98 % совсем недалеко до 99,9 %, но, если ошибки обходятся дорого, важно действовать постепенно. Улучшение с 85 до 90 % означает, что количество ошибок уменьшилось на треть. А с улучшением с 98 до 99,9 % ошибок стало в 20 раз меньше. Про такой показатель уже не скажешь «постепенно».
Падение цены на прогноз меняет и человеческую деятельность. Как первоначально компьютеры использовались для арифметических вычислений, таких как учет численности и разнообразные таблицы, так и первые прогнозы, полученные в результате машинного обучения, применялись для решения обычных прогностических задач. Помимо обнаружения мошенничества в них входили кредитоспособность, медицинская страховка и управление ресурсами.
Кредитоспособность – это прогноз вероятности погашения кредита заемщиком. Для медицинской страховки рассчитывали сумму, которую страхователь потратит на лечение. В управлении ресурсами важен прогноз загрузки склада в определенный день.
Не так давно возникли совершенно новые категории прогностических задач. Многие из них считались невыполнимыми до недавнего прогресса в технологии машинного интеллекта, в том числе распознавание объектов, языковой перевод и разработка лекарственных средств. Возьмем, к примеру, широко известный ежегодный конкурс ImageNet Challenge. Распознавание объектов – не всегда легкая задача и для человека. В данных ImageNet содержится множество категорий объектов, в том числе породы собак и другие схожие изображения. Не всегда можно уловить разницу между тибетским мастифом и бернским зенненхундом или между сейфовым и кодовым замком. Люди ошибаются примерно в 5 % случаев[22].
Если сравнивать первый (2010) и последний (2017) конкурсы, то прогнозы заметно улучшились. На рис. 1 приводится график точности победителей по годам. На вертикальной оси отмечена частота ошибок (поэтому чем ниже, тем лучше). В 2010 году лучшие прогностические машины неверно распознавали 28 % изображений. В 2012 году конкурсанты впервые использовали глубокое обучение, и частота ошибок снизилась до 16 %. Как отмечает профессор Принстона, IT-специалист Ольга Русаковская, «2012-й действительно стал годом огромного прорыва в точности, и это доказывает эффективность модели глубокого обучения, существующей уже несколько десятков лет»[23].
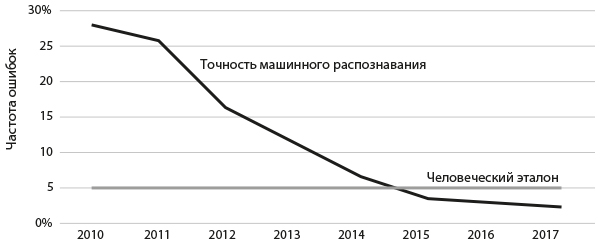
Рис. 1. Временной график ошибок в распознавании объектов
Алгоритмы улучшались быстро, впервые человеческий эталон был превзойден в 2015-м. К 2017 году у большинства участников было уже в два раза меньше ошибок. Машины стали распознавать объекты лучше человека[24].
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОК